Afin d'étudier, de simuler, de valider les algorithmes nous avons besoin de bases théoriques fournissant un ou des modèles pour l'algorithmique répartie. L'un de ces modèles est connu sous le nom de structure d'événements. Il est basé sur la décomposition des exécutions d'algorithmes répartis en événements élémentaires, partiellement ordonnés par une relation dite de causalité, et éventuellement complétée par une autre relation binaire entre événements : la relation de conflit.
L'exécution d'un algorithme réparti sera vu comme une succession d'événements, chacun d'eux se produisant sur un site donné. Cet événement sera constitué d'une réception de message, d'un calcul local au site, d'une émission de message ou d'une succession de telles opérations. Selon les besoins, on pourra considérer des événements "élémentaires" (un seul des trois cas ci-dessus) ou bien une suite d'opérations (en général réception d'un message, calculs locaux, émissions de messages). En fait, on regroupera dans un même événement tout ce qui a besoin d'être exécuté suite au phénomène déclanchant (en général réception de message) et qui ne doit pas être interrompu par d'autres actions : lorsqu'un site reçoit un message, cela nécessite le plus souvent des mises à jour de variables locales, des décisions à prendre et des messages à envoyer. On considèrera donc que l'exécution d'un événement est "atomique" : toutes les opérations qu'il contient doivent être exécutées avant de passer à l'événement suivant.
Les événements se produisant sur un même site sont totalement ordonnés parce qu'on a supposé que l'algorithme d'un site était séquentiel. L'ordre est donc induit par le temps : si deux événements se déroulent sur le même site, l'un d'eux a eu lieu avant l'autre.
Par contre, si deux événements se produisent sur des sites distincts, on ne peut pas dire dans le cas général que l'un d'eux a eu lieu avant l'autre. Il faudrait pour cela une horloge globale unique, et même dans ce cas, deux événements distincts pourraient être simultanés.
Toutefois, il est bien évident que si un des événements contient l'émission d'un message et que l'autre contient la réception du même message, alors le premier a eu lieu avant le second. Ceci fournit la base d'une relation d'ordre partiel sur les événements, appelée relation de causalité. On verra que celle-ci peut être "concrétisée" par le mécanisme des horloges logiques (la version scalaire de Lamport est simplement compatible avec cette relation, la version vectorielle de Fidge et Mattern caractérise vraiment la relation de précédence).
On définit tout d'abord la précédence comme ci-dessus : un événement e précéde un événement f si et seulement si :
Ainsi définie, la relation de précédence n'est pas une relation d'ordre. Pour ce faire, on ajoute la reflexivité (tout événement est inférieur ou égal à lui-même) et la transitivité (On dit que la relation d'ordre de causalité est la fermeture réflexive et transitive de la relation de précédence). Concrètement, deux événements distincts e et f seront tels que e < f pour la relation de causalité si et seulement si il existe une chaîne d'éléments e(1), e(2), ... e(n) tels que e=e(1) et f=e(n) et, pour tout i inférieur à n
Une structure d'événements est donc la donnée d'un ensemble E d'événements, fini ou au plus dénombrable, muni d'une relation d'ordre partiel notée par le signe < et appelée relation de causalité. Pour tout élément e de E, le passé de e est l'ensemble des événements qui lui sont inférieurs pour cette relation d'ordre. On supposera que le passé de tout événement est fini.
Deux événements non comparables pour la relation de causalité sont dits concomitants (on dit parfois concurrents par traduction un peu rapide de l'anglais).
On ajoute parfois une autre relation binaire dite de conflit notée # irreflexive, symétrique et vérifiant : si e' # e" et si e' < e, alors e # e" (persistance du conflit ou héritage du conflit vers le futur). Intuitivement, ceci correspond à un choix que doit faire le système à un moment donné, les deux alternatives s'excluant mutuellement. Bien entendu, deux événements en conflit sont concomitants. Des simulateurs ou validateurs pourront prendre en compte cette relation de conflit.
Nous utiliserons ces structures d'événements dans différents problèmes liés à l'observation d'un système réparti.
L'algorithme réparti sera généralement écrit sous la forme d'un ensemble de transitions, chacune d'elles pouvant s'exécuter sur un des sites du réseau. Les sites comportent éventuellement une variable d'état, dont la valeur pourra évoluer au passage d'une transition. Chaque transition comporte une condition de déclanchement, appelée garde de la transition, et des actions, locales au site ou envoi de messages. Des langages formels ont été créés dans le but de spécifier puis de simuler ce type d'algorithmes. En particulier, le langage LDS est couramment utilisé dans ce domaine. Un événement d'une exécution de l'algorithme correspondra alors à une occurence d'une transition franchie.
Même si on utilise pas de langage formel, l'écriture des algorithmes répartis s'inspirera de ce modèle. Voir les différentes version de l'algorithme de parcours parallèle, ou les exemples vus en TD.
Pour observer ou simuler un système, nous avons en fait besoin d'un ordre total sur les événements composant une exécution d'un algorithme réparti, cet ordre total devant bien entendu être compatible avec la relation de causalité (il serait aberrant d'observer un événement b avant un événement a si a précède b, par contre des événements concomitants peuvent être observés dans un ordre quelconque).
Étant donné une structure d'événements E et sa relation de causalité <, une horloge logique est une fonction h qui associe à chaque événement un entier, et qui vérifie : si e < f, alors h(e) < h(f). h(f) s'appelle la date logique de l'événement f. Bien entendu la condition ci-dessus n'est pas une équivalence, ne serait-ce que parce que la relation de causalité est une relation d'ordre partiel, alors que la comparaison des entiers est une relation d'ordre total. De plus, deux événements distincts peuvent avoir la même date.
Il est assez facile de mettre en oeuvre une telle horloge logique sur un système réparti, de manière à ce que tous les événements d'un même site aient des dates distinctes :
L'horloge ainsi définie satisfait bien la propriété de compatibilité demandée. En effet la propriété : si e < f, alors h(e) < h(f) est vraie parce que :
On note toutefois qu'une telle horloge logique n'induit pas un ordre total sur les événements : deux événements distincts peuvent avoir la même date s'ils se produisent sur des sites différents. lorsqu'on a vraiment besoin d'un ordre total, il suffira de "départager les ex-aequo" en prenant en compte les identités de sites si elles existent, ou un simple ordre aléatoire.
Ce type d'horloge logique peut par exemple être utilisé pour gérer une file d'attente répartie : voir le texte d'un algorithme gérant l'exclusion mutuelle dans un réseau quelconque.
L'objectif est ici d'obtenir une caractérisation simple de la relation de causalité au moyen d'une horloge logique, donc de faire en sorte que la propriété : si e < f, alors h(e) < h(f) admette une réciproque. Il est bien évident que la relation d'ordre sur les horloges ne peut pas être totale comme celle sur les entiers. On définit donc une fonction H qui associe à tout événement e un vecteur de nombres entiers indicé par l'ensemble des sites de la manière suivante :
On montre que cette horloge caractérise la relation de causalité : En effet :
Compte-tenu de l'absence de temps global dans un système réparti, il est difficile d'observer, de détecter des propriétés globales d'un tel système. C'est par contre facile si on utilise un simulateur : le système réparti étant simulé sur une machine, les événements sont exécutés selon un ordre total, compatible avec la relation de précédence, et on peut, entre chaque événement, avoir une vision globale de l'état des sites et des canaux.
Si par contre on est dans un système réparti réel, la seule solution pour tester l'état du système est de lancer un AUTRE algorithme réparti qui observe le premier. Mais les messages de cet algorithme de supervision doivent eux aussi emprunter les canaux de communication disponibles, donc leur diffusion n'est pas immédiate, ils ne peuvent observer simultanément ce qui se passe dans tous les sites et les canaux, et de plus ils s'intercalent dans les canaux entre les messages de l'algorithme observé. Des techniques spécifiques doivent donc être développées pour résoudre ces problèmes (cf. TD)
Quelques problèmes classiques d'observation d'état global :
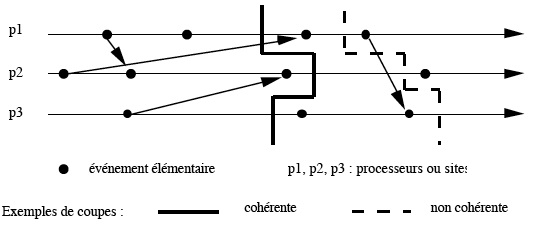
Une exécution d'un algorithme réparti est constituée d'un ensemble d'événements élémentaires (strictement locaux à un site, ou réception de message ou émission de message). Cet ensemble d'événements est partiellement ordonné par la relation de précédence.
Une coupe (ou coupure) C est un ensemble d'événements tel que: si f appartient à C, si g précède f, et si f et g sont deux événements se produisant sur le même site, alors g appartient à C.
La coupe C est dite cohérente si cette dernière propriété est également vraie même lorsque les deux événements ne se produisent pas sur le même site (cf. exemple ci-dessous).
Une coupe peut être associée à un état global du système.
Soit une coupe C. On considère, pour chaque site i, l'état obtenu après le dernier événement (le plus grand au sens de la relation de précédence) du site i et appartenant à C, et on considère les messages émis par un élément de C et reçus par un événement n'appartenant pas à C.
On peut voir sur un exemple simple qu'un l'état global
observé ne correspond pas nécessairement à un état
réellement atteint au cours de l'exécution d'un algorithme d'observation.
Considérons une exécution d'un algorithme observé schématisée
par :
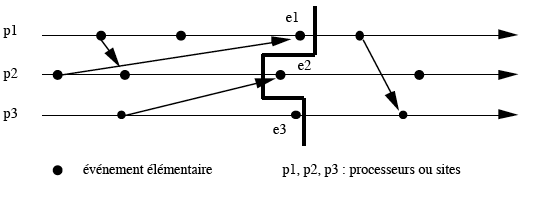
La coupe représentée par la ligne brisée en gras est cohérente,
mais ne correspond pas à un état réel du système
à un instant donné. Elle englobe en effet un événement
e1 de p1 et un événement e3 de p3, qui ont eu lieu après
un événement e2 de p2 qu'elle n'englobe pas. Cette coupure peut
correspondre à un état global obtenu par un algorithme d'observation
si, par exemple, le site p2 est l'initiateur de cet algorithme et a lancé
la demande d'état avant e2, et que p1 et p3 ont reçu leur premier
message de demande d'état après e1 et e3.
Les algos étudiés ici n'utilisent pas les horloges logique, ou du moins peuvent s'en passer (voir l'exemple vu en cours pour cela), il s'agit ici de détection de propriétés globales.
Construction d'un algorithme de détection de terminaison à partir de la définition de la terminaison. Cet algorithme est valable
pour tout type de réseau, et est validé par le fait qu'il se construit logiquement à partir de la définition.
Un algorithme qui teste si un ensemble de sites est interbloqué : détection d'interblocage. Ici on ne teste pas la terminaison (l'algorithme étudié peut éventuellement ne pas se terminer, par exemple parce qu'il a pour rôle d'agir en permanence sur un réseau dans le quel se déroulent des événements en permanence, mais de détecter un dysfonctionnement qui bloquerait tout ou partie de son action.
Les deux exemples ci-dessus sont pour le premier une détection de
BONNE propriété (terminaison d'un algorithme qui DOIT se terminer), et
pour le second la détection d'une MAUVAISE propriété (blocage total ou
partiel d'un algorithme qui DOIT continuer son travail). On peut se
poser la question de la faisabilité d'un algorithme qui permettrait à
un site superviseur d'obtenir une suite d'états globaux généraux de
l'ensemble des sites du réseau permettant à ce superviseur de vérifier
diverses propriétés par calcul centralisé sur les états ainsi obtenus.
Comme le superviseur ne pas pas tout voir instantanément, le problème majeur réside dans la synchronisation des observations des différents sites. On peut envisager d'utiliser les horloges logiques de Lamport pour cela, ou plus simplement un marqueur pour synchroniser les requêtes.
Le texte de cet exercice propose la construction d'un tel algorithme.
Retour au sommaire algorithmique répartie